
supervised learning 的缺点:
- little labelled data available
- generating labels is expensive
Unsupervised learning
- Discover structure in only X1, X2, …, Xp
- Part of explorative data analysis, very useful in data science
- Main problem: no clear way to check the answer
- Two types of approaches: dimensionality reduction, clustering
Principal component analysis(PCA)
find a linear low-dimensional representation that captures as much variation in the data as possible( projection from p dimensions to d < p)
Dimensionality reduction
- How to investigate high-dimensional data? scatterplots, correlation or covariance, select most interesting
概念
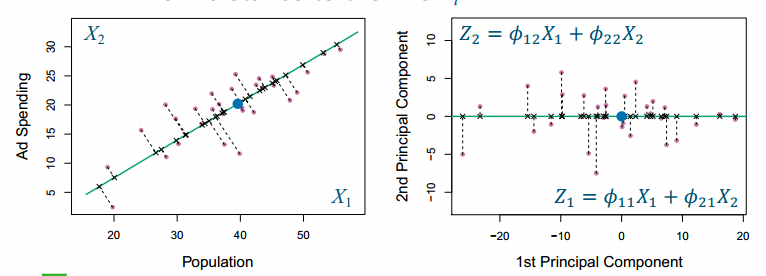
- Projecting points on a line Zi (principal component, PC): maximum variation along the line Zi数据在这个方向上的分布变化幅度最大,也就是minimum distance to the line Zi通过最大化方差来选择主成分方向,等价于通过最小化距离来选择低维子空间。
- Principal components are ordered: Z1 is the direction of most variation,Z2 is the direction of most variation perpendicular to Z1, Z3 is the direction of most variation perpendicular to Z1 and Z2
Find the first principal component

 通过使载荷向量的长度最大化(1)来最大化方差
通过使载荷向量的长度最大化(1)来最大化方差size does matter
- Scaling to unit standard deviation is useful if features have different ranges
- Scaling is essential if measured in different units,
- If units are the same, maybe we do not want to scale to unit variance as we may inflate noise这是因为单位方差假设所有特征的方差应该相等,但在这种情况下,这种假设可能不合适。
biplot
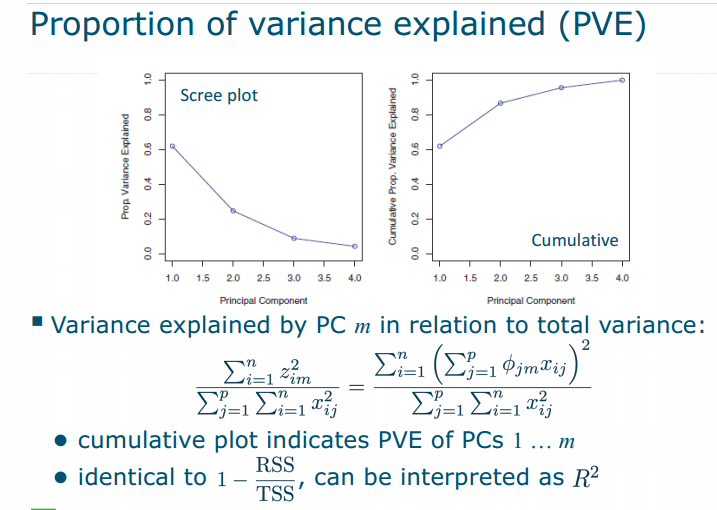
PVE(proportion of variance explained)
 就是那个loading vector就是PC的系数值, 同时也是pca.component_(如果在df才拟合的话),也就是z
就是那个loading vector就是PC的系数值, 同时也是pca.component_(如果在df才拟合的话),也就是z
How to choose number of PCs?
- As few PCs as possible, retaining as much information as possible
- no clear solution: scree plot(PVE90%-95%); regard as tuning parameter, optimize by cross-validation; use additional information; visualization(2D,3D)
Another interpretion of PCA
- Projecting points back into original space
- PCA minimizes reconstruction error
Limitation and Solutions
- Linearity: kernel PCA (last week)
- Orthogonality:independent component analysis (ICA), maximizes independence of components
Clustering vs. classification
- Classification:build predictors for categories based on an example dataset with labels
- Clustering:find ”natural” groups in data without using labels
- Classes and clusters do not necessarily coincide!
- Classes can consist of multiple clusters, clusters can combine classes

- Define what is “far apart” and “close together”: need a distance (or dissimilarity) measure to capture what we think is important for the grouping the choice for a certain distance measure is often the most important choice in clustering!
- Clustering is an ill-defined problem –there is no such thing as the objective clustering
Hierarchical clustering
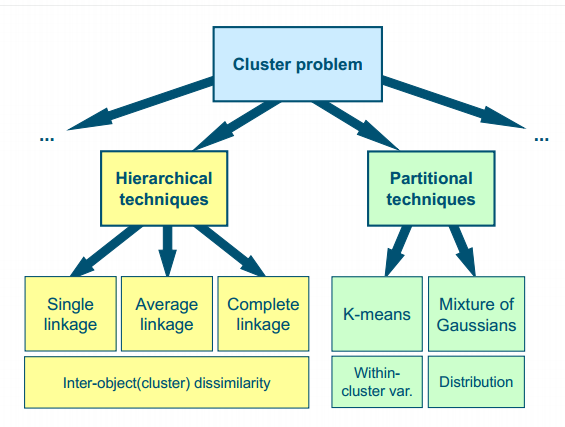
Hierarchical clustering
- create dendrogram (tree) assuming clusters are nested
- bottom-up or agglomerative (as opposed to top-down, e.g. as in decision tree or K-means)
- Cutting the dendrogram(树状图) decides on number of clusters(簇)
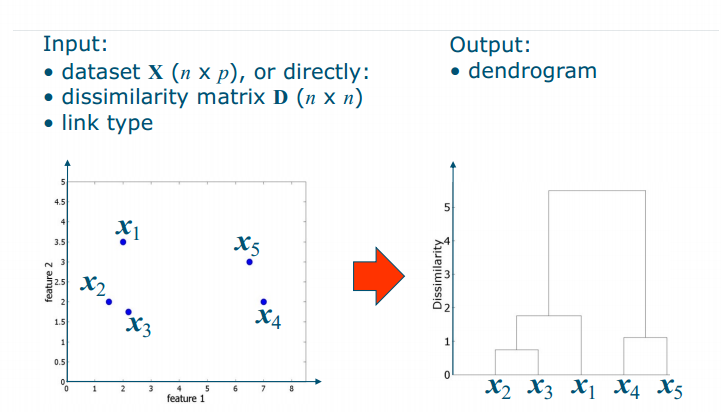
Algorithm
- start: all objects of X in a separate cluster
- clustering: combine (fuse) the 2 clusters with the shortest distance in dissimilarity matrix D
- distance between clusters is based on link type:
- single, complete, average, centroid, …
- repeat until only 1 cluster is left
Steps
- Step 1: Find the most similar pair of clusters: here x2 and x
- Step 2: Fuse x2 and x3 into a cluster [x2, x3]
- Step 3: Recompute D –what is the dissimilarity between [x2, x3] and the rest?
- single link: the smallest dissimilarity (nearest neighbor)
- complete link: the largest dissimilarity
- average link: the average dissimilarity
- centroid link: the dissimilarity to the cluster centroid

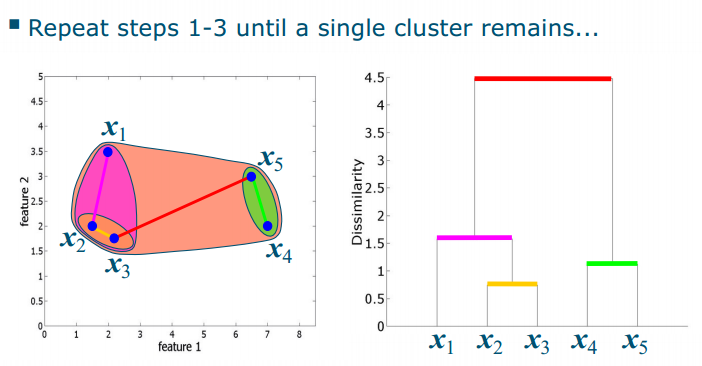
- Finally, cut the dendrogram to obtain clusters(Number of clusters: cut largest “gap” in tree (cf. elbow))
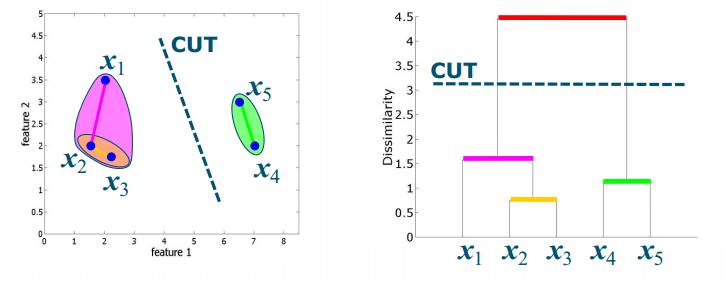 exercise
exercise 
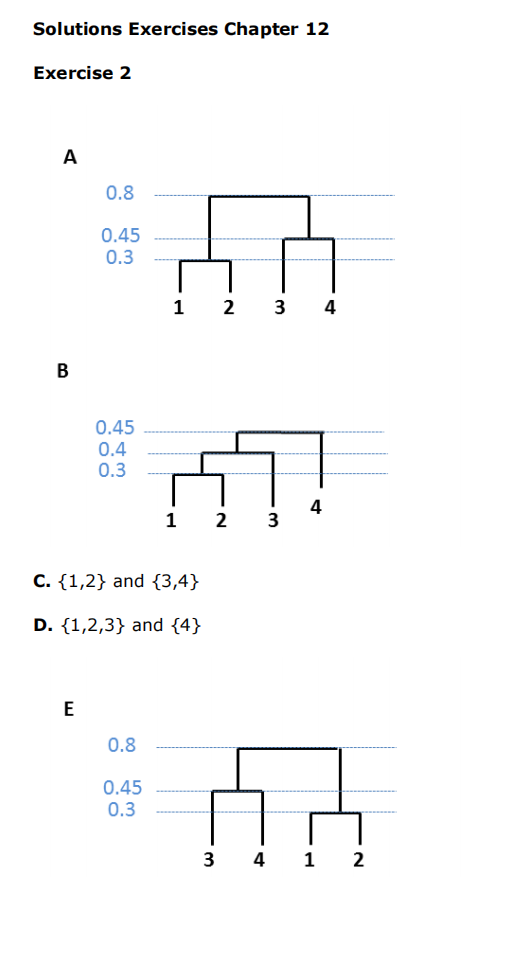
Linkage
No single best option:depends on data and intended use
- Average/centroid and complete linkage generally give more balanced trees
- Single linkage can find non-globular clusters, but is sensitive to outliers
- Centroid linkage can give inversions
Scaling
- Depending on dissimilarity measure used, feature scaling can influence results (e.g. Euclidean distance) or not (e.g. correlation)
- When using Euclidean distance
- centering to mean zero to focus on trends instead of absolute value
- different measurement units may be a reason to scale to unit standard deviation
Recap
- Unsupervised learning ● discover structure in only X, without a Y
- Dimensionality reduction: ● find low-dimensional representation that captures as much information as possible ● linear vs. nonlinear
- Principal component analysis: ● find orthogonal directions that maximize preserved variation or (equivalently) minimize reconstruction error ● scores, loadings, biplots
- Clustering: ● finding natural groups in data ● requires clustering algorithm and dissimilarity measure ● essentially subjective, no “proof”
- Hierarchical clustering: ● repeatedly fuse clusters, create dendrogram ● choice of linkage: single, complete, average, centroid ● cut dendrogram to find actual clusters