
Neurons and gradient descent
- Neural nets are interconnected networks of simple processing units, a.k.a neurons
- It remains just a parallel, the artificial neuron is just an approximation!
 The output y was modelled as a weighted linear combination of inputs xj. Moreover, a transfer function, or activation function was used to make a decision.
The output y was modelled as a weighted linear combination of inputs xj. Moreover, a transfer function, or activation function was used to make a decision.Gradient descent–how to find the right weights?
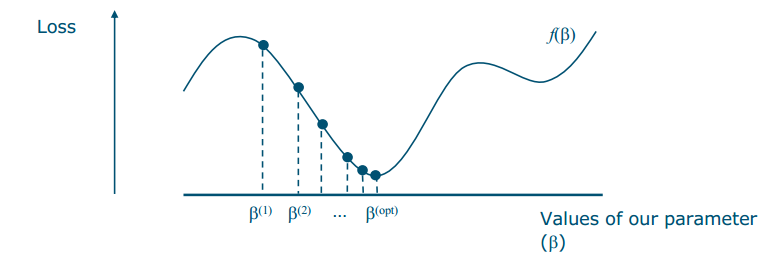
- We want to find the minimum of an error function
- We start with an initial guess of the parameter b
- We change its value in the direction of maximal slope (导数Derivatives are slopes)
- We continue until reaching a minimum
Steps
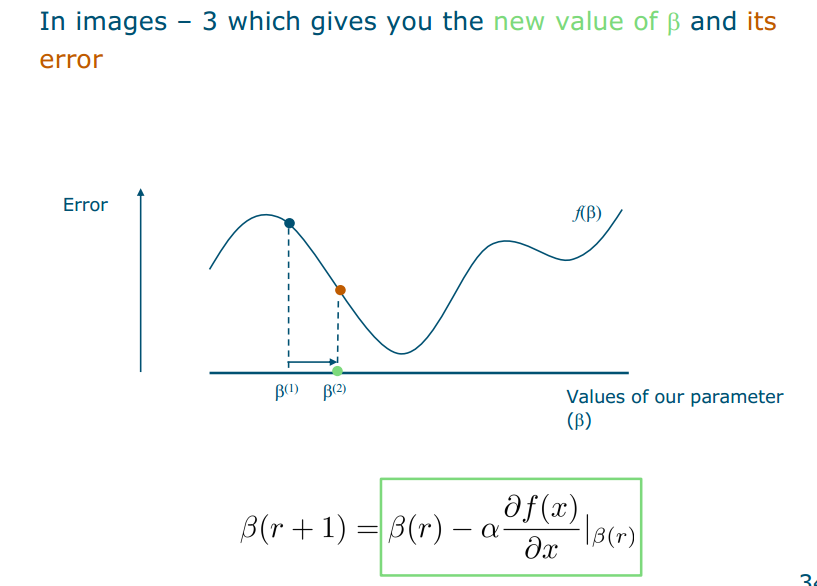
- To update a weight b, we remove to its value the derivative
- a is called a learning rate»It decides by how much you multiply the step vector»Large a can lead to faster convergence than small» too large a can lead to disaster
- r is the iteration
- Why the minus sign? Because we want to move towards a minimum!
Momentum

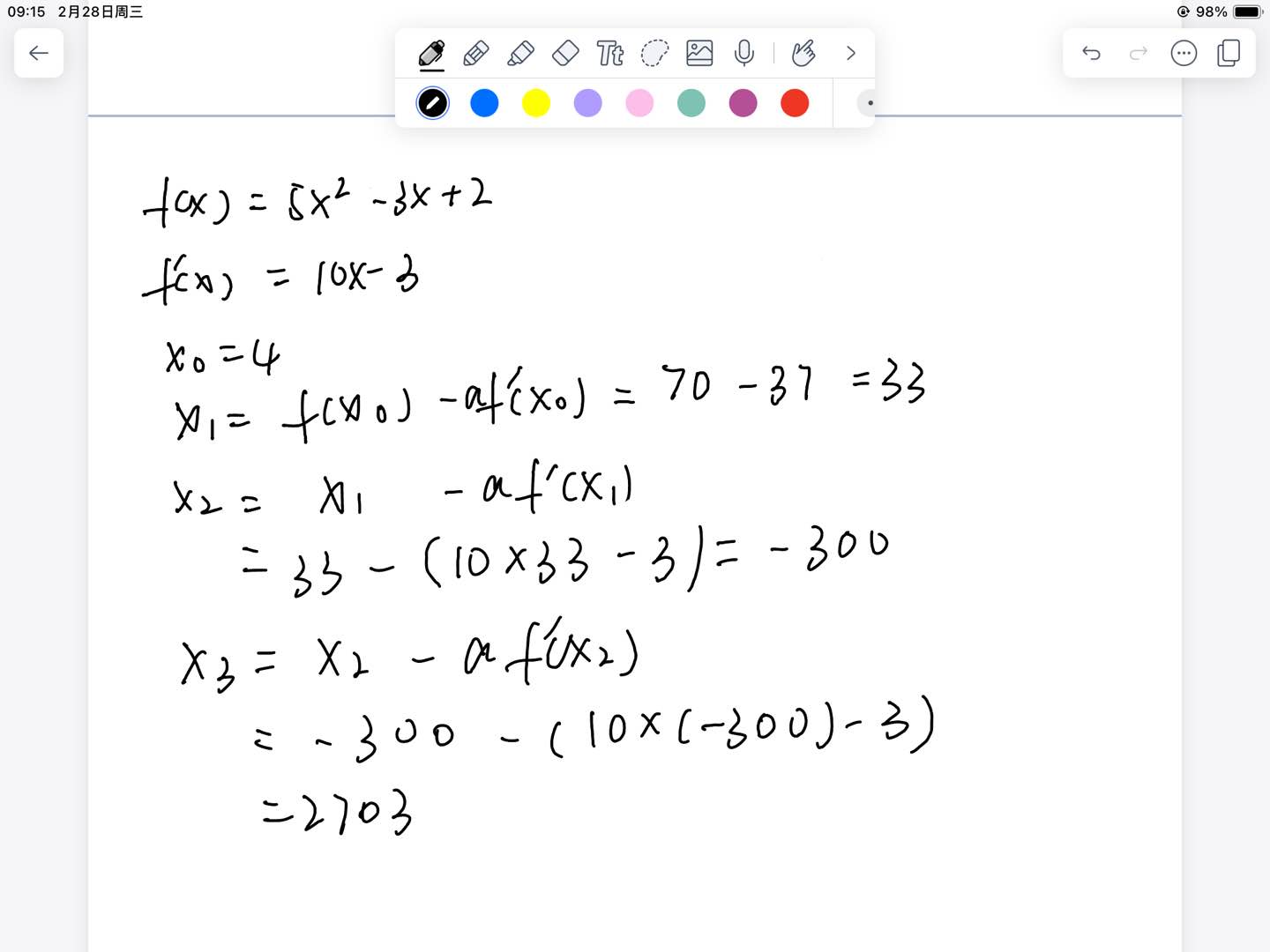
Numerical example
Learning rate controls oscillation and speed Momentum uses a bit of the previous step

the models using them multi-layer perceptron convolutional neural networks ( deep learning)
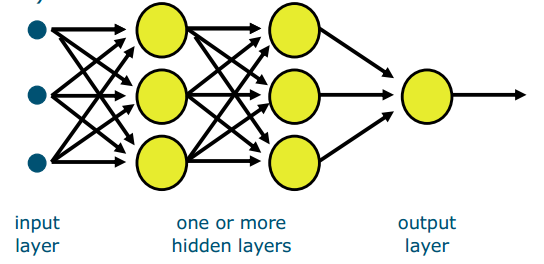
Multilayer perceptron (MLP)
(from linear classifier to nonlinear version)
- It’s a feed forward network: it goes from inputs to outputs, without loops
- Every neuron includes an activation function (e.g. sigmoid, see earlier slides)
Chain rule
- How to compute gradient descent on a cascade级联 of operations?
- How to reach all trainable weights?

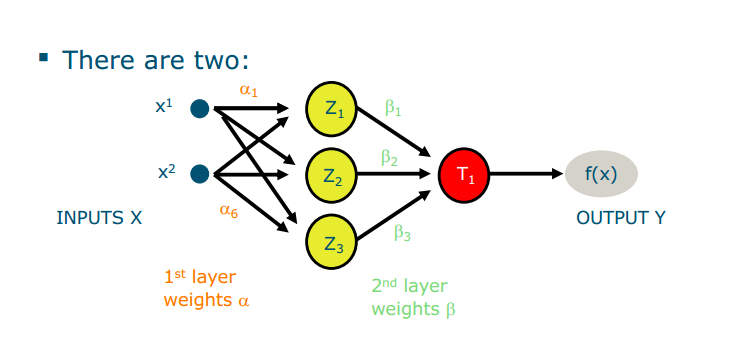
- The forward pass: you put a data point in and obtain the prediction
- The Backward pass: you update parameters by back-propagating errors exercise Describe the architecture of the following network. ● How many layers are there? 2 ● How many neurons per layer? 3,1 ● How many trainable parameters (weights and biases)?10
Convolutional Neural Networks(CNN)
- they proposed a network learning spatial filters on top of spatial filters. They were (and are) called convolutional neural networks
- The CNN was considered interesting, but very hard to train. It needed● Loads of training data > nobody had them● A lot of computational power > same
Change
big data graphic processing
How to work
- They are conceptually very similar to MLPs
- But their weights (b) are 2D convolutional filters
- For this, they are very well suited for images
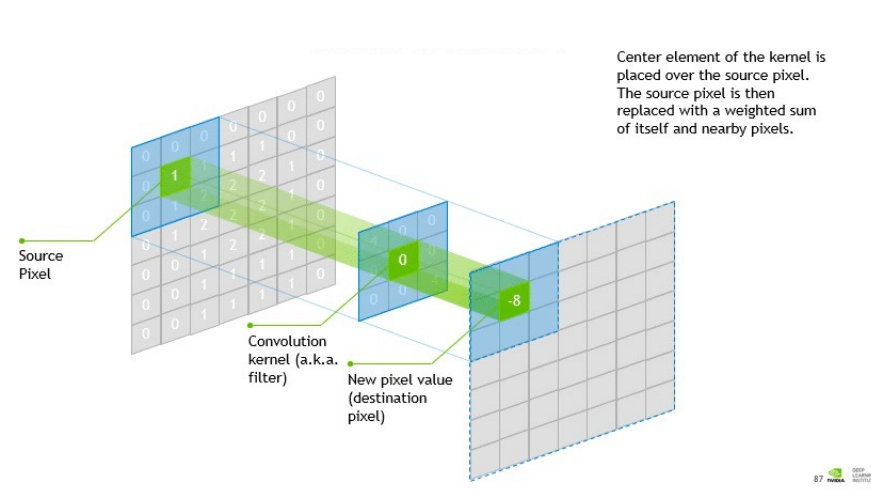

- In convolutional neural networks, the filters are spatial (on 2D grids). ● local : they convolve the values of the image in a local window● shared: the same filter is applied everywhere in the image: why shared? “Recycling” the same operation allows to have much less parameters to learn!
Learn
- By “learns”, I mean adapt filters weights to minimize prediction error (i.e. backpropagation)
Steps
- Convolutional filters start with random numbers
- Iteratively they are improved: each coefficient is updated in the direction of largest gradient of the cost function
- At the end, the filters become quite meaningful!
Summary
- Perceptrons are “neuron-inspired” linear discriminants
- Multilayer perceptrons are trainable, nonlinear discriminants
- Feed-forward neural networks in general can be used for classification, regression and feature extraction
- There is a large body of alternative neural nets
- Key problems in the application of ANNs are choosing the right size and good training parameters
- Convolutional neural networks have a constrained architecture encoding prior knowledge of the problem
- Deep learning is concerned with constructing extremely large neural networks that depend on:● special hardware (GPUs), to be able to train them● specific tricks (e.g. rectified linear units) to prevent overfitting
文档信息
- 本文作者:Xinyi He
- 本文链接:https://buliangzhang24.github.io/2024/02/17/MachineLearning-11.-Nueural-networks-and-deep-learning/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)