
Y= f(X)+e Y: (response, dependent variable, predicted value) X: (predictor,independent variable,feature) f: unknow relationship e: random error(1. with 平均值等于0 mean zero 2. 模拟了个体之间的差异) the multivariate case:Usually more than 2 input dimensions! p: number of input dimensions 要分析几个变量 n: number of data points(samples in the data) in a sample 样本量
Prediction
是啥?就是找到Y就行了,f这个关系可以是一个黑盒 Y and f are ==unknown== , so we estimate f in order to predict Y from konwn X values 有帽子的f 和Y是estimated / predicted f is ==estimated== using ==training data==, consisting of X values and corresponding Y values. Then, the Y values can be ==predicted== for new X values 如果说e 的平均值是0, 那么 Y^ = f(X)^
Error of the model
Y- Y with hat - Can be estimated from the data set: mean squared error: 1/N sum(yi-yi with hat)^2
Reducible and irreducible error
reducible : change the ==learning techniques and models ==and ==better training data== » minimized while estimating f (inference) irreducible: cannot be reduced because of ==unmeasured but relevant inputs ==or ==unmeasured variation(nosie)==» set upper bound on the accuracy of predicting Y(prediction)
Inference
就是虽然俺们也预测了Y,但是重要的是找到f 关系的方程 estimate f , but ==understanding how== X influence Y Do not treat f with hat as black box
Summary
Prediction: estimating f^ to get good prediction of Y^ Inference: estimating f ^ to get an understanding of the relationship between X1-Xp and Y
Prediction accuracy vs. model interpretablity
预测准确度:预测准确度是指模型在测试集上的预测结果与实际观测值之间的一致程度 模型解释度:线性回归模型通常具有很高的解释性,因为它可以明确地表示变量之间的线性关系,并且可以解释每个自变量对因变量的影响程度 ==linear models==: high interpretability and sometimes high accuracy»inference ==highly non-linear==: low interpretability, high accuracy»prediction Choice depends:prediction or inference
Parametric methods
choose the functional form of f, then learn its parameters from training data,using least squares or a differenct method 就是先假设确定了一个方法去作为f,然后求参数 ad:
- much easier to estimate a set of parameters than to fit an arbitrary function
- ==less training data== dis: if the chosen functional form is too far from the truth, prediction and inference results can be poor >we don’t know the relationship in advance
Non parametric
based on training data itself非参数方法不需要事先确定模型的函数形式或者参数的数量,而是从数据中直接学习模型的结构。这使得非参数方法在处理复杂的数据结构或者对数据分布了解不充分时更具有灵活性。 ad: ==good fit== ,even if the input-output relations are complex dis:
- require much ==more training data==
- risk of ==overfitting== modelling 了 the nosie e (don’ t have enough data) Overfitting是指模型在训练数据上表现很好,但在测试数据(或新数据)上表现较差的现象,因为噪声等»指模型过于复杂,过度拟合了训练数据中的噪声和细微特征的情况。 Overfitting 的原因有: 模型过于复杂,训练数据量不足,特征选择不当,训练数据和测试数据的分布不一致

Supervised vs Unsupervised Learning
最大区别在有没有标签
Assessing Model Accuracy
Measuring the quality of fit
回归和分类的区别 回归:预测连续的变量 分类:预测离散的变量
Mean squared error(regression)
- training MSE isnot important: 增加模型的灵活性可以使其更容易适应复杂的数据模式和关系,从而可能降低训练 MSE。more flexiblity less taining MSE。
- test MSE(unseen) different parts of field
- ==goal: select the model with the smallest test MSE==
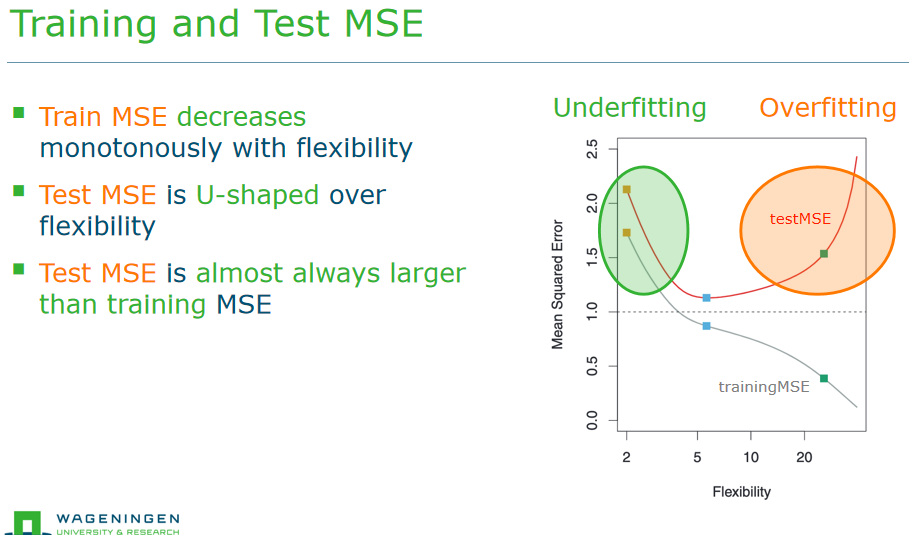 Underfitting:模型过于简单,无法捕捉数据中的真实模式和关系的情况。欠拟合的模型通常对训练数据和测试数据的表现都较差 Overfitting:模型过于复杂,过度拟合了训练数据中的噪声和细微特征的情况。过拟合的模型在训练数据上表现很好,但在未见过的测试数据上表现较差
Underfitting:模型过于简单,无法捕捉数据中的真实模式和关系的情况。欠拟合的模型通常对训练数据和测试数据的表现都较差 Overfitting:模型过于复杂,过度拟合了训练数据中的噪声和细微特征的情况。过拟合的模型在训练数据上表现很好,但在未见过的测试数据上表现较差Bias vs. variance
 因为Biase和variance,所以MSE才是U形的
因为Biase和variance,所以MSE才是U形的Bias : model too simple
- Bias refers to the error that is introduced by approximating a real-life problem by a too simpler model真实值和期望值之间的差异
- 无论我们使用多少训练数据,这个误差都会存在
- more flexible methods have less bias
Variance: model too complex
- 如果换成不同的training sample, f的预测有多大的变化
- 如果model 有High variance,就是很小的变化都会在f的预测结果上产生很大的变化方差越大意味着模型对数据的变化更敏感。
- more flexible methods have higher variance ==more flexible, less bias, more variance== Good test set performance requires ==low variance as well as low squared bias.==
 (a) inflexible biase »fiexible Flexible is generally better. A flexible method has many degrees of freedom, so it can follow the patterns in the data, even if they are highly non-linear. If the data is more linear, there are enough data points to train the parameters so that the model turns out more linear as well. If flexibility is chosen extremely large, overfitting could still occur. 大样本量:对于极大的样本量,灵活的模型往往表现更好,因为它们有更多的数据可供学习 predictor 量少:当预测变量的数量较少时,意味着数据可能具有简单的关系,这种关系可以由灵活的模型充分捕获而无需担心过拟合 (b) inflexible There is a high risk of overfitting. (c) flexible (d) inflexible (flexible model» there lots of nosiy » fiting the nosiy) 就是用对了,就是low,low。
(a) inflexible biase »fiexible Flexible is generally better. A flexible method has many degrees of freedom, so it can follow the patterns in the data, even if they are highly non-linear. If the data is more linear, there are enough data points to train the parameters so that the model turns out more linear as well. If flexibility is chosen extremely large, overfitting could still occur. 大样本量:对于极大的样本量,灵活的模型往往表现更好,因为它们有更多的数据可供学习 predictor 量少:当预测变量的数量较少时,意味着数据可能具有简单的关系,这种关系可以由灵活的模型充分捕获而无需担心过拟合 (b) inflexible There is a high risk of overfitting. (c) flexible (d) inflexible (flexible model» there lots of nosiy » fiting the nosiy) 就是用对了,就是low,low。 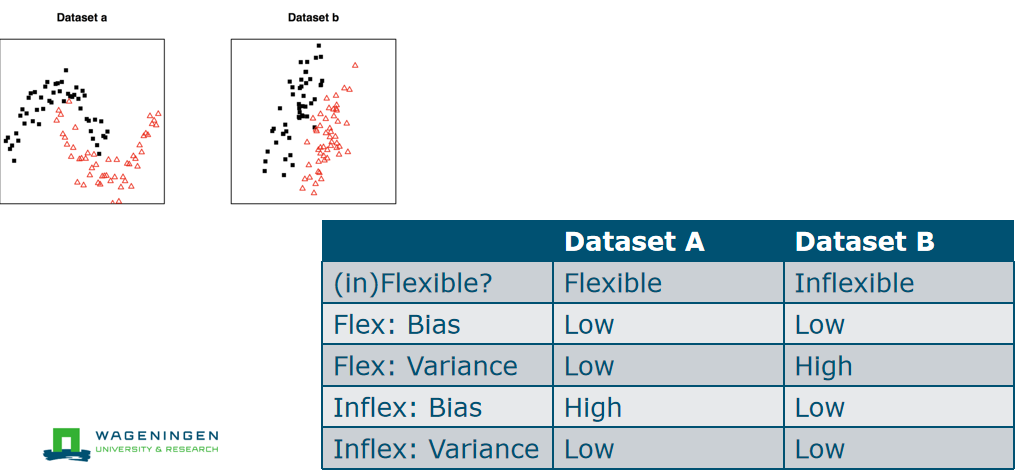
For Classification Setting
Instead of MSE, we get ==error rate==:I= 1 if the pefect model Again, there is a ==training error rate and a test error rate==. They express the fraction of incorrect classifications不正确分类的比例
Training set and test set
就是用training set 去训练模型,然后在调整参数的时候用validation set 找哪个参数合适,同时也找哪个模型是更适合这个数据的,再去test set里面验证这个模型好不好
- Training set to ==train the model==
- Validation set to ==optimize the hyper parameters==
- Test set to test the performance of the model on an ==independent ==part of the data set. To get an estimate on how good it will ==work in practice==
with limited amount of data 少量数据
可以用 cross validation

文档信息
- 本文作者:Xinyi He
- 本文链接:https://buliangzhang24.github.io/2024/02/02/MachineLearning-1.-Statistical-learning/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)